Este desafio tem como objetivo testar a capacidade de criação e implementação de APIs, uso de containers Docker e scraping de dados via web crawler.
-
Construir uma camada de APIs
-
O engenheiro poderá escolher a ferramenta que desejar, sendo sugeridas ferramentas como FastAPI, Django, ou outra de preferência.
-
A estrutura da API deverá ser clara e organizada, facilitando futuras manutenções e expansões.
A estrutura da API, incluindo os arquivos e diretórios, poderá ser definida conforme a preferência do engenheiro. Abaixo um exemplo sugerido utilizando FastAPI:
├── app/ │ ├── main.py # Arquivo principal da API │ ├── services.py # Módulo para lógica de scraping │ ├── models.py # Modelos de dados e schemas ├── Dockerfile # Arquivo para build da imagem Docker ├── requirements.txt # Dependências da aplicação (se usar FastAPI) └── README.md # Documentação do projeto`
-
-
Deploy via Docker
-
Toda a estrutura da aplicação deverá ser disponibilizada para deploy utilizando Docker.
-
A imagem Docker deverá ser capaz de rodar localmente e em ambiente de produção, seguindo as melhores práticas de containerização.
A estrutura Docker deverá conter um Dockerfile bem definido, contendo as instruções para construção do ambiente da API. Abaixo um exemplo de Dockerfile:
# Use uma imagem base do Python FROM python:3.9-slim # Crie um diretório de trabalho WORKDIR /app # Copie os arquivos de dependências COPY requirements.txt . # Instale as dependências RUN pip install -r requirements.txt # Copie o código da aplicação COPY . . # Exponha a porta 8000 para a aplicação EXPOSE 8000 # Comando para rodar a API CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
-
-
Endpoint: Consulta Incra
- A API deverá fornecer um endpoint chamado Consulta Incra.
- Este endpoint deverá realizar um web crawler ou scraping da página do Mapa ONR (https://mapa.onr.org.br/), selecionando a camada Incra para extrair os dados necessários.
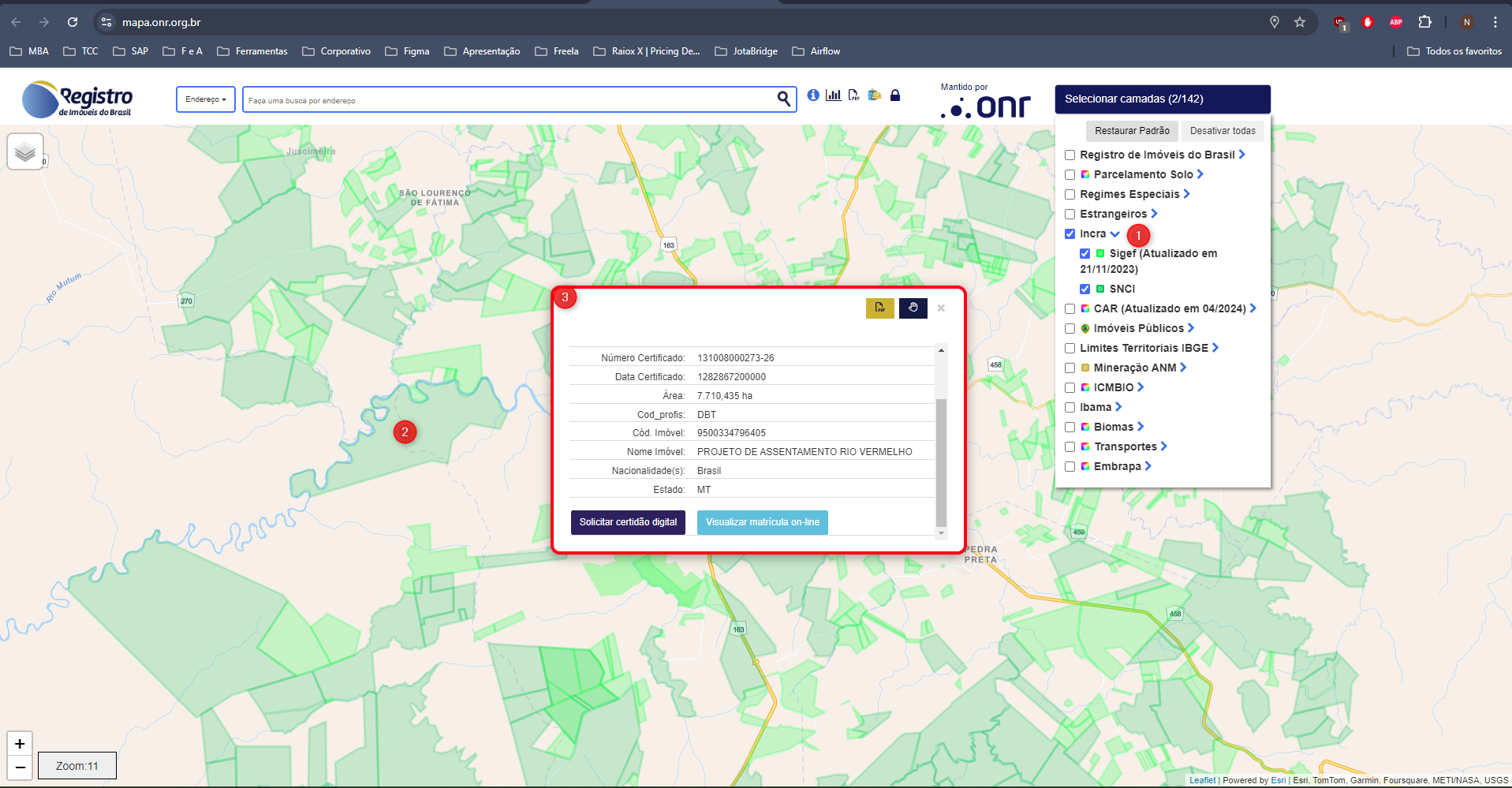
-
URL do endpoint:
/consulta-incra -
Método HTTP:
GET -
Parâmetros de Solicitação: A estrutura dos parâmetros de solicitação pode ser definida pelo engenheiro. Alguns exemplos de parâmetros sugeridos:
-
limit: Indicador limite de resultados. -
offset: Quantidade de registros que serão "pulados". -
retorna_geometric: Indentifica se retornará ou não poligonos. -
Estrutura da Resposta:
-
O retorno deverá ser em formato JSON com os dados coletados. Abaixo um exemplo de estrutura de resposta:
JSON
{ "estado": "MT", "Cidade": "Jaciara", "propriedades": [ { "id": "12345", "codigo_imovel":"codigo_imo", "nome": "Fazenda Modelo", "area": "500", "situacao": "REGISTRADA", "status":"CERTIFICADA", "data_aprovacao": "01/04/2022" }, ... ] }
- Documentação
- Documentar todas as etapas para construção da API.
- Sugere-se a utilização de ferramentas como Markdown para testes unitários.
Os seguintes aspectos serão avaliados durante o desafio:
a. Qualidade do Código
- Clareza e organização do código.
- Utilização de boas práticas de desenvolvimento.
- Estruturação eficiente dos arquivos e módulos da aplicação.
b. Funcionamento da API
- A API deverá responder corretamente às solicitações feitas, de acordo com os parâmetros especificados.
c. Containerização com Docker
- O uso correto de Docker para criação e funcionamento do(s) container(s).
d. Documentação
- Clareza na documentação do projeto, explicando como rodar a aplicação, como foi construido o endpoint, exemplos de requisições e respostas, entre outros detalhes importantes.
- Instruções sobre como configurar o ambiente e rodar a aplicação usando Docker.
e. Robustez do Web Scraping
- Implementação de um scraping eficiente e que lide com possíveis erros ou mudanças no layout da página.
- Tolerância a erros, como quando a página alvo não está disponível ou mudanças ocorrem na estrutura do HTML.
f. Escalabilidade e Extensibilidade
- A solução deverá ser facilmente escalável para novos endpoints ou modificações futuras.
- Estrutura da API deve permitir fácil manutenção e novas implementações de funcionalidades.
g. Performance
- A API deverá responder de forma eficiente e rápida, mesmo em situações de carga moderada.
- O scraping deve ser otimizado para obter os dados com o menor tempo possível sem sobrecarregar a página de origem.