diff --git a/python/llm/evaluation/building-a-custom-evaluator.ipynb b/python/llm/evaluation/building-a-custom-evaluator.ipynb
deleted file mode 100644
index 4a1aa32..0000000
--- a/python/llm/evaluation/building-a-custom-evaluator.ipynb
+++ /dev/null
@@ -1,602 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "id": "hdr-logo",
- "metadata": {},
- "source": [
- "\n",
- " \n",
- "  \n",
- "
\n",
- "
\n",
- " Docs\n",
- " |\n",
- " GitHub\n",
- " |\n",
- " Slack Community\n",
- "
\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "title",
- "metadata": {},
- "source": [
- "# Using a Benchmark Dataset to Build a Custom LLM as a Judge Evaluator"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "intro",
- "metadata": {},
- "source": [
- "In this tutorial, you'll learn how to build a custom LLM-as-a-Judge Evaluator tailored to your specific use case. While Arize AX provides several [pre-built evaluators](https://arize.com/docs/ax/evaluate/llm-as-a-judge/arize-evaluators-llm-as-a-judge) that have been tested against benchmark datasets, these may not always cover the nuances of your application.\n",
- "\n",
- "So how can you achieve the same level of rigor when your use case falls outside the scope of standard evaluators?\n",
- "\n",
- "The discipline is simple: **don't trust a judge until you've measured it against ground truth.** We'll build a small benchmark dataset from a handful of human-annotated examples, then use it to build and refine a custom evaluator — measuring how often the judge agrees with the human labels, and iterating the judge prompt until that agreement is high enough to trust. The use case we'll explore is data extraction from an image of a receipt.\n",
- "\n",
- "To follow along, you'll need:\n",
- "\n",
- "* A free [Arize AX](https://app.arize.com/auth/join) account\n",
- "* An OpenAI API Key"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "setup-hdr",
- "metadata": {},
- "source": [
- "## Set up Keys and Dependencies"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "pip",
- "metadata": {},
- "outputs": [],
- "source": [
- "%pip install -qqqq arize arize-otel openinference-instrumentation-openai openai nest_asyncio pandas"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "keys",
- "metadata": {},
- "outputs": [],
- "source": [
- "import os\n",
- "import pandas as pd\n",
- "import nest_asyncio\n",
- "from getpass import getpass\n",
- "\n",
- "nest_asyncio.apply()\n",
- "\n",
- "\n",
- "if \"SPACE_ID\" not in os.environ:\n",
- " os.environ[\"SPACE_ID\"] = getpass(\"🔑 Enter your Arize Space ID: \")\n",
- "\n",
- "if \"API_KEY\" not in os.environ:\n",
- " os.environ[\"API_KEY\"] = getpass(\"🔑 Enter your Arize API Key: \")\n",
- "\n",
- "if \"OPENAI_API_KEY\" not in os.environ:\n",
- " os.environ[\"OPENAI_API_KEY\"] = getpass(\"🔑 Enter your OpenAI API Key: \")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "tracing-hdr",
- "metadata": {},
- "source": [
- "# Configure Tracing"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "register",
- "metadata": {},
- "outputs": [],
- "source": [
- "from arize.otel import register\n",
- "from openinference.instrumentation.openai import OpenAIInstrumentor\n",
- "\n",
- "MODEL = \"gpt-5.4-mini\"\n",
- "JUDGE_MODEL = \"gpt-4.1\"\n",
- "\n",
- "tracer_provider = register(\n",
- " space_id=os.environ[\"SPACE_ID\"],\n",
- " api_key=os.environ[\"API_KEY\"],\n",
- " project_name=\"receipt-classifications\",\n",
- ")\n",
- "OpenAIInstrumentor().instrument(tracer_provider=tracer_provider)"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "traces-hdr",
- "metadata": {},
- "source": [
- "# Generate Image Classification Traces"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "traces-desc",
- "metadata": {},
- "source": [
- "In this tutorial, we'll ask an LLM to generate expense reports from receipt images provided as public URLs. Running the cells below will generate traces, which you can explore directly in Arize AX for annotation. We'll use `gpt-5.4-mini`, which supports image inputs.\n",
- "\n",
- "\n",
- "Dataset Information:\n",
- "Jakob (2024). Receipt or Invoice Dataset. Roboflow Universe. CC BY 4.0. Available at: https://universe.roboflow.com/jakob-awn1e/receipt-or-invoice (accessed on 2025-07-29)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "urls",
- "metadata": {},
- "outputs": [],
- "source": [
- "import uuid\n",
- "import pandas as pd\n",
- "urls = [\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/8M5px2yLoNtZ6gOQ2r1D/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/8EVgYMNObyV6kLqBNeFG/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/86aohWmcEfO0XkflO8AB/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/1eGPBChz7wvovQROk2l8/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/0WqR2GSfGmxWB7ozo3Pj/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/FAEJRtviIboCYSKFZcEZ/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/0AoEaFy8FAw6DVieWCa8/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/0Q3hAyNwXNpHTeoWU7fz/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/2r876u4WpaCYFdMPwieK/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/2ZWeE0yO0oJUDtpgEAPY/original.jpg\",\n",
- "\"https://source.roboflow.com/HahhKcbQqdf8YAudM4kU3PuVCS72/37PF6xfHyuqzIBdO7Kgw/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/6mo4M0nJeKZEsdKrRfsR/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/5ezJ8tUBGbNnt0jZi2JU/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/4BCIWGazhCj03oTMWboO/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/4B8vXJNwJ7ZuHEWyjgAv/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/2EpeKbAqsSwciH2IHGyV/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/2LP3g9rKZrYDkNB3I78c/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/1hT6iLEIAFBw8W70u2FY/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/1zaKpaDhRPxkiIDTvMuc/original.jpg\",\n",
- "\"https://source.roboflow.com/Zf1kEIcRTrhHBZ7wgJleS4E92P23/1hF1R2Pt41hnlqhlXLDD/original.jpg\"\n",
- "]"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "extract",
- "metadata": {},
- "outputs": [],
- "source": [
- "from openai import OpenAI\n",
- "client = OpenAI()\n",
- "\n",
- "def extract_receipt_data(input):\n",
- " response = client.chat.completions.create(\n",
- " model=MODEL,\n",
- " messages=[\n",
- " {\n",
- " \"role\": \"user\",\n",
- " \"content\": [\n",
- " {\"type\": \"text\", \"text\": \"Analyze this receipt and return a brief summary for an expense report. Only include category of expense, total cost, and summary of items\"},\n",
- " {\n",
- " \"type\": \"image_url\",\n",
- " \"image_url\": {\n",
- " \"url\": input,\n",
- " },\n",
- " },\n",
- " ],\n",
- " }\n",
- " ],\n",
- " )\n",
- " return response"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "run-extract",
- "metadata": {},
- "outputs": [],
- "source": [
- "import time\n",
- "\n",
- "for url in urls:\n",
- " extract_receipt_data(url)\n",
- "\n",
- "# Flush the traces so they're queryable when you annotate / export them.\n",
- "tracer_provider.force_flush()\n",
- "time.sleep(5)"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "dataset-hdr",
- "metadata": {},
- "source": [
- "# Create Benchmarked Dataset"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "annotate-desc",
- "metadata": {},
- "source": [
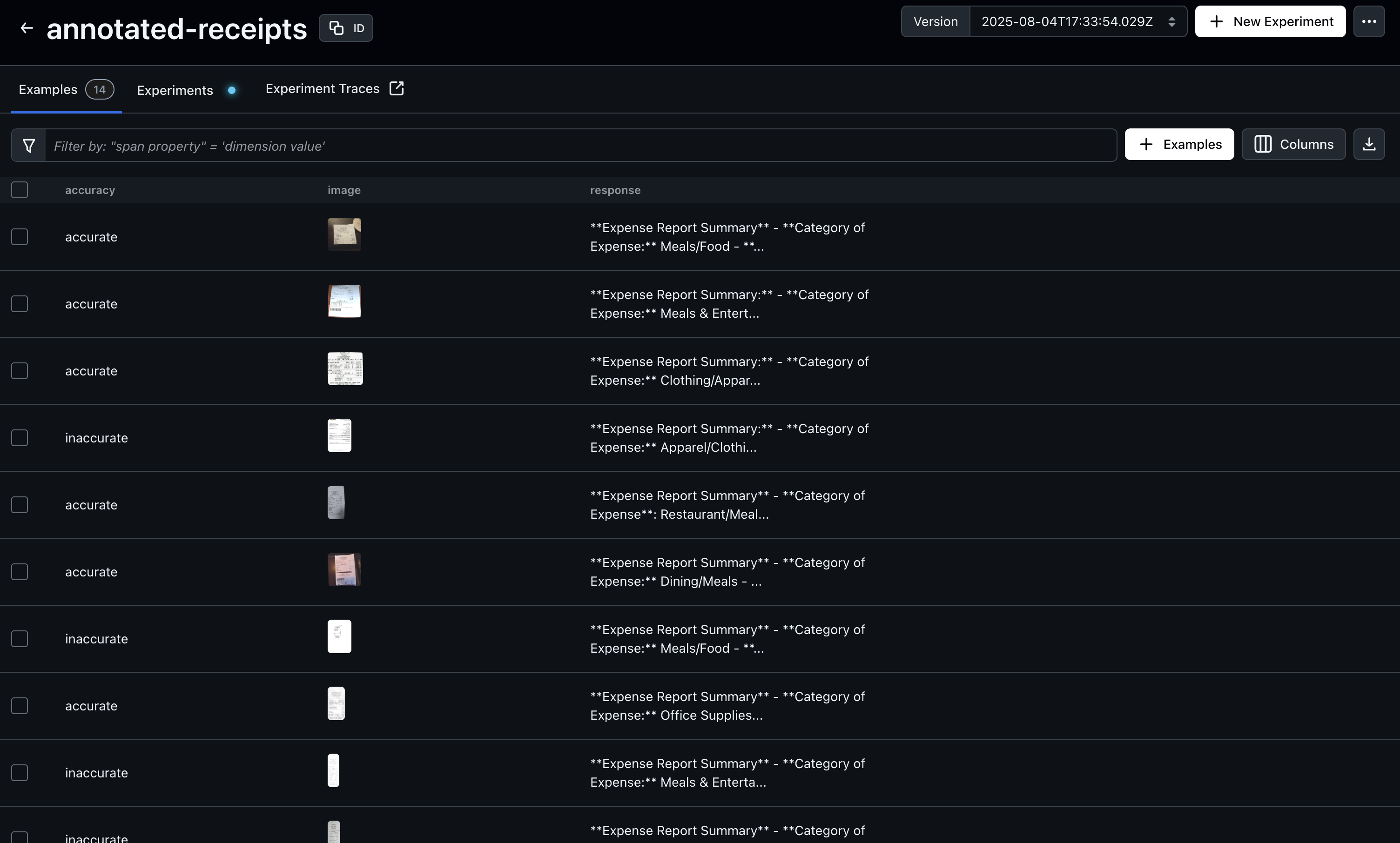
- "After generating traces, open Arize AX to begin annotating your dataset. In this example, we'll annotate based on \"accuracy\", but you can choose any evaluation criterion that fits your use case. Just be sure to update the query below to match the annotation key you're using—this ensures the annotated examples are included in your benchmark dataset.\n",
- "\n",
- "Run the cell below to see annotations in action:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "video",
- "metadata": {},
- "outputs": [],
- "source": [
- "from IPython.display import HTML\n",
- "\n",
- "video_url = \"https://storage.googleapis.com/arize-phoenix-assets/assets/videos/arize-annotation.mp4\"\n",
- "\n",
- "HTML(f\"\"\"\n",
- "\n",
- "\"\"\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "export",
- "metadata": {},
- "outputs": [],
- "source": [
- "from datetime import datetime, timedelta, timezone\n",
- "\n",
- "from arize.client import ArizeClient\n",
- "\n",
- "ax_client = ArizeClient(api_key=os.environ[\"API_KEY\"])\n",
- "\n",
- "print(\"#### Exporting your traces into a dataframe.\")\n",
- "\n",
- "primary_df = ax_client.spans.export_to_df(\n",
- " space_id=os.environ[\"SPACE_ID\"],\n",
- " project_name=\"receipt-classifications\",\n",
- " start_time=datetime.now(timezone.utc) - timedelta(days=50),\n",
- " end_time=datetime.now(timezone.utc),\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "filter",
- "metadata": {},
- "outputs": [],
- "source": [
- "filtered_df = primary_df[\n",
- " (primary_df[\"annotation.accuracy.label\"].notna())\n",
- "][[\n",
- " \"attributes.input.value\",\n",
- " \"attributes.output.value\",\n",
- " \"annotation.accuracy.label\",\n",
- "]].rename(columns={\n",
- " \"attributes.input.value\": \"image\",\n",
- " \"attributes.output.value\": \"response\",\n",
- " \"annotation.accuracy.label\": \"accuracy\"\n",
- "})\n",
- "\n",
- "filtered_df"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "flatten",
- "metadata": {},
- "outputs": [],
- "source": [
- "import json\n",
- "\n",
- "def extract_url(input_value):\n",
- " data = json.loads(input_value)\n",
- " return data[\"messages\"][0][\"content\"][1][\"image_url\"][\"url\"]\n",
- "\n",
- "def extract_content(input_value):\n",
- " data = json.loads(input_value)\n",
- " return data[\"choices\"][0][\"message\"][\"content\"]\n",
- "\n",
- "filtered_df[\"image\"] = filtered_df[\"image\"].apply(extract_url)\n",
- "filtered_df[\"response\"] = filtered_df[\"response\"].apply(extract_content)\n",
- "\n",
- "\n",
- "filtered_df"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "create-dataset",
- "metadata": {},
- "outputs": [],
- "source": [
- "from datetime import datetime, timezone\n",
- "\n",
- "DATASET_NAME = f\"annotated-receipts-{datetime.now(timezone.utc):%Y%m%d-%H%M%S}\"\n",
- "dataset = ax_client.datasets.create(\n",
- " space=os.environ[\"SPACE_ID\"],\n",
- " name=DATASET_NAME,\n",
- " examples=filtered_df,\n",
- ")\n",
- "DATASET_NAME"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "dataset-img",
- "metadata": {},
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "template-hdr",
- "metadata": {},
- "source": [
- "# Create the custom judge"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "template-desc",
- "metadata": {},
- "source": [
- "Next we'll build a baseline judge and benchmark it against the annotations. The judge is an LLM-as-a-Judge that *reads the receipt image* and the model's expense report, and classifies the report as `accurate`, `almost accurate`, or `inaccurate` — the same labels a human annotator used. `make_judge(prompt)` binds one judge prompt into a task we can run as an experiment; the experiment's evaluator then checks whether the judge's label matches the human annotation."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "judge-v1",
- "metadata": {},
- "outputs": [],
- "source": [
- "RAILS = [\"accurate\", \"almost accurate\", \"inaccurate\"]\n",
- "\n",
- "JUDGE_PROMPT_V1 = \"\"\"You are an evaluator tasked with assessing the quality of a model-generated expense report based on a receipt.\n",
- "\n",
- "MODEL OUTPUT (Expense Report):\n",
- "{output}\n",
- "\n",
- "The input receipt image is attached. Evaluate the report and assign exactly one label:\n",
- "- \"accurate\" - Fully correct\n",
- "- \"almost accurate\" - Mostly correct\n",
- "- \"inaccurate\" - Substantially wrong\n",
- "\n",
- "Respond with only the label.\"\"\"\n",
- "\n",
- "\n",
- "def make_judge(prompt):\n",
- " \"\"\"Bind one judge prompt into an experiment task. The task reads the receipt\n",
- " image and the model's report from the dataset row and returns one rail label.\"\"\"\n",
- "\n",
- " def task_function(dataset_row):\n",
- " response = client.chat.completions.create(\n",
- " model=JUDGE_MODEL,\n",
- " temperature=0,\n",
- " messages=[\n",
- " {\n",
- " \"role\": \"user\",\n",
- " \"content\": [\n",
- " {\"type\": \"text\", \"text\": prompt.format(output=dataset_row[\"response\"])},\n",
- " {\"type\": \"image_url\", \"image_url\": {\"url\": dataset_row[\"image\"]}},\n",
- " ],\n",
- " }\n",
- " ],\n",
- " )\n",
- " verdict = response.choices[0].message.content.strip().lower()\n",
- " # Map the reply onto one of the rails (check the longer labels first, since\n",
- " # \"accurate\" is a substring of \"almost accurate\").\n",
- " for rail in [\"almost accurate\", \"inaccurate\", \"accurate\"]:\n",
- " if rail in verdict:\n",
- " return rail\n",
- " return verdict\n",
- "\n",
- " return task_function"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "evaluator",
- "metadata": {},
- "outputs": [],
- "source": [
- "from arize.experiments import EvaluationResult\n",
- "\n",
- "\n",
- "def matches_annotation(output, dataset_row) -> EvaluationResult:\n",
- " \"\"\"Score the judge: does its label match the human annotation for this example?\"\"\"\n",
- " expected = dataset_row[\"accuracy\"]\n",
- " if output == expected:\n",
- " return EvaluationResult(\n",
- " score=1.0, label=\"correct\", explanation=\"Judge label matches the human annotation\"\n",
- " )\n",
- " return EvaluationResult(\n",
- " score=0.0,\n",
- " label=\"incorrect\",\n",
- " explanation=f\"Judge said '{output}', annotation was '{expected}'\",\n",
- " )"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "run-v1",
- "metadata": {},
- "outputs": [],
- "source": [
- "experiment_v1, results_v1 = ax_client.experiments.run(\n",
- " space=os.environ[\"SPACE_ID\"],\n",
- " dataset=DATASET_NAME,\n",
- " task=make_judge(JUDGE_PROMPT_V1),\n",
- " evaluators=[matches_annotation],\n",
- " name=\"Initial Experiment\",\n",
- ")\n",
- "results_v1[\"eval.matches_annotation.score\"].mean()"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "iter1-hdr",
- "metadata": {},
- "source": [
- "# Iteration 1 to improve the evaluator prompt"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "iter1-desc",
- "metadata": {},
- "source": [
- "Next, we'll refine our judge prompt by adding more specific classification rules. We can add these rules based on gaps we saw in the previous iteration. This additional guidance helps improve accuracy and ensures the evaluator's judgments better align with human expectations."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "judge-v2",
- "metadata": {},
- "outputs": [],
- "source": [
- "JUDGE_PROMPT_V2 = \"\"\"You are an evaluator tasked with assessing the quality of a model-generated expense report based on a receipt.\n",
- "\n",
- "MODEL OUTPUT (Expense Report):\n",
- "{output}\n",
- "\n",
- "The input receipt image is attached. Evaluate the report and assign exactly one label:\n",
- "- \"accurate\" - Total price, itemized list, and expense category are all accurate. All three must be correct to get this label.\n",
- "- \"almost accurate\" - Mostly correct but with small issues. For example, the expense category is too vague.\n",
- "- \"inaccurate\" - Substantially wrong or missing information. For example, an incorrect total price.\n",
- "\n",
- "Respond with only the label.\"\"\""
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "run-v2",
- "metadata": {},
- "outputs": [],
- "source": [
- "experiment_v2, results_v2 = ax_client.experiments.run(\n",
- " space=os.environ[\"SPACE_ID\"],\n",
- " dataset=DATASET_NAME,\n",
- " task=make_judge(JUDGE_PROMPT_V2),\n",
- " evaluators=[matches_annotation],\n",
- " name=\"Stronger Prompt Experiment\",\n",
- ")\n",
- "results_v2[\"eval.matches_annotation.score\"].mean()"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "iter2-hdr",
- "metadata": {},
- "source": [
- "# Iteration 2 to improve the evaluator prompt"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "iter2-desc",
- "metadata": {},
- "source": [
- "To further improve our evaluator, we'll add few-shot guidance to the prompt. These examples help highlight common failure cases and guide the evaluator toward more consistent and generalized judgments."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "judge-v3",
- "metadata": {},
- "outputs": [],
- "source": [
- "JUDGE_PROMPT_V3 = \"\"\"You are an evaluator tasked with assessing the quality of a model-generated expense report based on a receipt.\n",
- "\n",
- "MODEL OUTPUT (Expense Report):\n",
- "{output}\n",
- "\n",
- "The input receipt image is attached. Evaluate the report and assign exactly one label:\n",
- "- \"accurate\" - Total price, itemized list, and expense category are accurate. All three must be correct to get this label.\n",
- " An incorrect category is one that is overly vague (e.g., \"Miscellaneous\", \"Supplies\") or does not accurately reflect the itemized list.\n",
- " For example, \"Dining and Entertainment\" should not be grouped together if the itemized list only includes food.\n",
- " Reasonable general categories like \"Office Supplies\" or \"Groceries\" are acceptable if they align with the listed items.\n",
- "- \"almost accurate\" - Mostly correct but with small issues. For example, the expense category is too vague.\n",
- " If a category includes extra fields (e.g., \"Dining and Entertainment\" but the receipt only includes food) mark this as almost accurate.\n",
- "- \"inaccurate\" - Substantially wrong or missing. For example, an incorrect total price, or one or more missing items, makes the result inaccurate.\n",
- "\n",
- "Respond with only the label.\"\"\""
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "run-v3",
- "metadata": {},
- "outputs": [],
- "source": [
- "experiment_v3, results_v3 = ax_client.experiments.run(\n",
- " space=os.environ[\"SPACE_ID\"],\n",
- " dataset=DATASET_NAME,\n",
- " task=make_judge(JUDGE_PROMPT_V3),\n",
- " evaluators=[matches_annotation],\n",
- " name=\"Few Shot Experiment\",\n",
- ")\n",
- "results_v3[\"eval.matches_annotation.score\"].mean()"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "final-hdr",
- "metadata": {},
- "source": [
- "# Final Results"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "final-desc",
- "metadata": {},
- "source": [
- "Each experiment reports the share of examples where the judge's label matched the human annotation — that agreement rate is how you know whether to trust the judge. Compare the three runs in the **Experiments** tab of your dataset (or from the `results_*` dataframes above) and watch the agreement climb as the prompt is refined.\n",
- "\n",
- "Once your evaluator reaches a performance level you're satisfied with, it's ready for use. The target score will depend on your benchmark dataset and specific use case. That said, you can continue applying the techniques from this tutorial to refine and iterate until the evaluator meets your desired level of quality."
- ]
- },
- {
- "cell_type": "markdown",
- "id": "final-img",
- "metadata": {},
- "source": [
- ""
- ]
- }
- ],
- "metadata": {
- "language_info": {
- "name": "python"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 5
-}